NCPI FHIR Implementation Guide - Local Development build (v0.2.0). See the Directory of published versions
Modular Ig
While interoperability is a primary objective for using FHIR, research data by it’s very nature is quite varied. Much of the data requires approval before access is permitted, yet researchers must know the data exists before they can begin the approval process. Because of issues such as these, the IG itself is broken into modules designed to support specific use cases. For a FHIR server hosting a certain dataset, those building the ETL need only concern themselves with the modules that apply to the use cases describing the datasets they are working with.
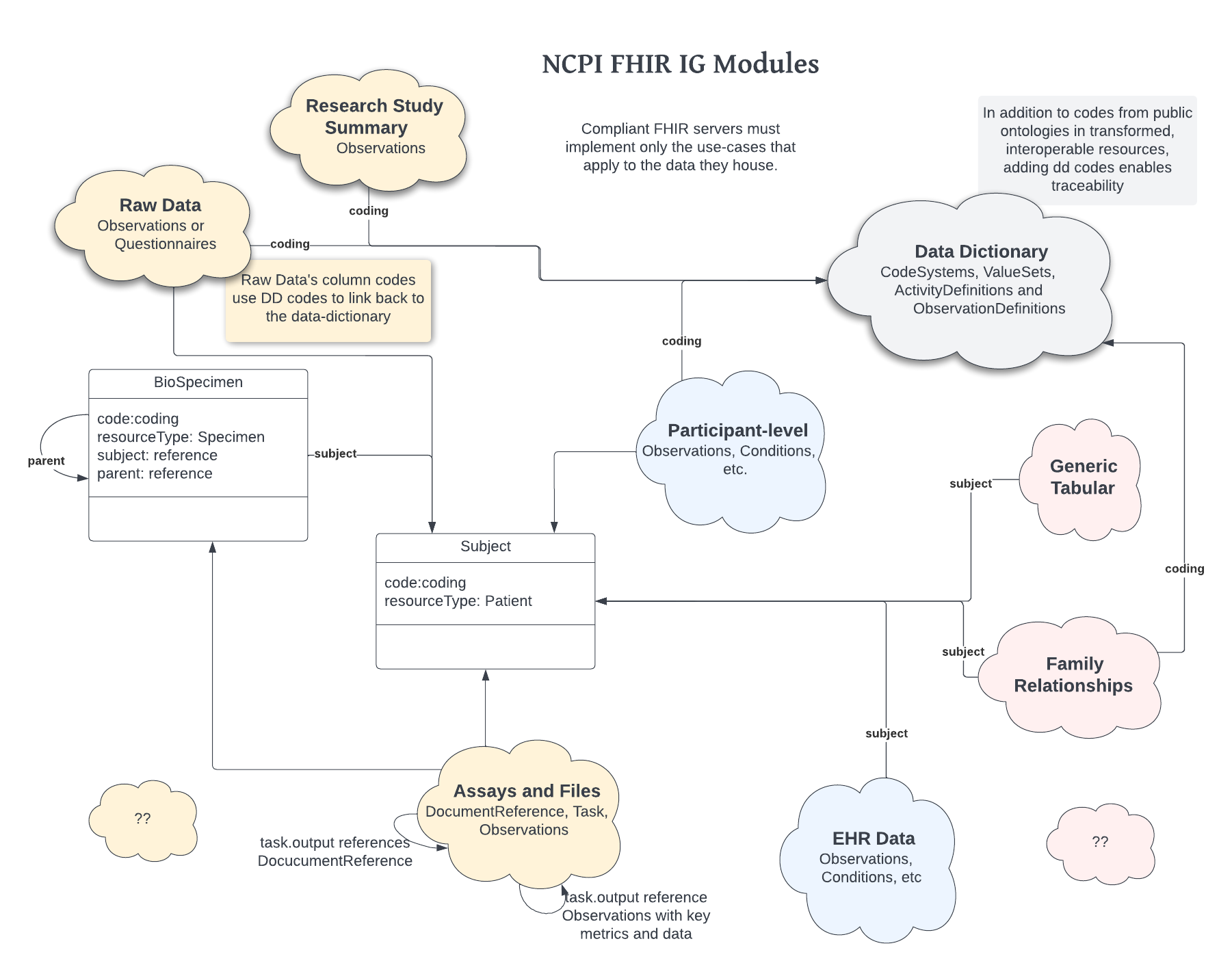
Some use cases, such as the Data Dictionary component, may be useful across many or even all of the servers implementing the NCPI FHIR IG while others, such as Family Relationships, apply only to a fraction of those servers. Study summary and meta-data would likely lack traditional restrictions on their accessibility and could be hosted on a public server, while row-level, restricted data would be require some sort of authorization to access.
Administrators for these FHIR servers should selectively apply only those module profiles that apply to the machines expected use cases, providing clear delineation for what sorts of data can be found therein.